SvectorDB: Base de datos vectorial sin servidor en menos de 2 minutos

En la era de los datos, la eficiencia y velocidad son cruciales. SvectorDB revoluciona la gestión de datos al ofrecer una base de datos vectorial sin servidor que se puede implementar en menos de 2 minutos. Este sistema no solo simplifica la infraestructura, sino que también optimiza el procesamiento y almacenamiento de datos complejos, ideal para aplicaciones de inteligencia artificial y aprendizaje automático. Con SvectorDB, los desarrolladores pueden concentrarse en innovar sin preocuparse por la administración de servidores, lo que reduce costos y aumenta la productividad. Este artículo explorará sus características, ventajas y pasos para su implementación rápida.
- Introducción a SvectorDB: Base de datos vectorial sin servidor en menos de 2 minutos
- ¿Qué es una base de datos vectorial sin servidor?
- Características de las Bases de Datos Vectoriales Sin Servidor
- Aplicaciones Comunes de las Bases de Datos Vectoriales Sin Servidor
- Ventajas de las Bases de Datos Vectoriales Sin Servidor
- Arquitectura de una Base de Datos Vectorial Sin Servidor
- Desafíos en la Implementación de Bases de Datos Vectoriales Sin Servidor
- ¿Qué diferencia hay entre un servidor y una base de datos?
- ¿Qué son los datos vectoriales?
- Preguntas Frecuentes de Nuestra Comunidad (FAQ)
Introducción a SvectorDB: Base de datos vectorial sin servidor en menos de 2 minutos
En esta sección, aprenderás cómo SvectorDB es una solución eficaz para almacenar y recuperar datos vectoriales de manera eficiente, sin la necesidad de administrar un servidor propio. Con SvectorDB, puedes implementar rápidamente un sistema de archivos vectoriales que se adapta a tus necesidades, todo ello en menos de 2 minutos.
¿Qué es SvectorDB?
SvectorDB es una base de datos vectorial que opera en un modelo serverless. Esto significa que no necesitas preocuparte por la infraestructura subyacente, ya que se encarga automáticamente de escalar y administrar los recursos necesarios para mantener tu base de datos en funcionamiento. SvectorDB es ideal para aplicaciones que requieren búsqueda y recuperación de datos vectoriales, como sistemas de recomendación, búsqueda de similitudes y procesamiento de lenguaje natural.
Características principales de SvectorDB
SvectorDB ofrece una serie de características que lo hacen una opción atractiva para proyectos de datos vectoriales:
- Escalabilidad automática: Se adapta dinámicamente a la carga de trabajo, asegurando que siempre tengas los recursos necesarios.
- Bajo mantenimiento: No requiere configuración ni administración de servidores, lo que reduces el tiempo y los costos operativos.
- Rendimiento optimizado: Proporciona velocidades de búsqueda y recuperación de datos muy rápidas.
- Seguridad integrada: Ofrece medidas de seguridad robustas para proteger tus datos.
- API fácil de usar: Permite integrar SvectorDB en tu aplicación con facilidad y rapidez.
Cómo implementar SvectorDB en 2 minutos
La implementación de SvectorDB es sencilla y rápida. Sigue estos pasos:
- Regístrate: Crea una cuenta en el servicio de SvectorDB.
- Crea una base de datos: Configura tu primera base de datos vectorial a través de la interfaz de usuario o la API.
- Integra la API: Utiliza la API proporcionada para insertar y consultar datos vectoriales en tu aplicación.
- Optimiza y prueba: Realiza pruebas y optimiza la configuración según tus necesidades específicas.
Uso de SvectorDB en aplicaciones prácticas
SvectorDB es especialmente útil en diversas aplicaciones prácticas:
- Sistemas de recomendación: Mejora la precisión y la velocidad de recomendaciones basadas en contenido vectorial.
- Búsqueda de similitudes: Encuentra rápidamente elementos similares en un conjunto de datos vectoriales.
- Procesamiento de lenguaje natural: Almacena y recupera representaciones vectoriales de texto para tareas de NLP.
- Análisis de imágenes: Utiliza representaciones vectoriales de imágenes para búsquedas y clasificaciones.
- IoT y sensores: Gestiona y analiza datos vectoriales generados por dispositivos IoT.
Comparación con otras bases de datos vectoriales
A continuación, se presenta una comparación de SvectorDB con otras bases de datos vectoriales:
| Característica | SvectorDB | Base de datos X | Base de datos Y |
|---|---|---|---|
| Modelo de despliegue | Serverless | On-premises | Hybrid |
| Escalabilidad | Automática | Manual | Automática |
| Mantenimiento | Bajo | Alto | Medio |
| Rendimiento | Excelente | Bueno | Bueno |
| Seguridad | Integrada | Personalizable | Integrada |
¿Qué es una base de datos vectorial sin servidor?

Una base de datos vectorial sin servidor es un sistema de almacenamiento y gestión de datos que utiliza representaciones vectoriales (vectores numéricos) para almacenar y recuperar información. A diferencia de las bases de datos tradicionales que almacenan datos en formato tabular, las bases de datos vectoriales almacenan datos en vectores, lo que facilita la realización de operacionesadvanced de búsqueda y comparación, como la búsqueda de similitudes y vecinos más cercanos. La característica sin servidor (serverless) significa que la base de datos se ejecuta en la nube y se escala automáticamente según la demanda, sin que el usuario tenga que preocuparse por la gestión del hardware o el software subyacente.
Características de las Bases de Datos Vectoriales Sin Servidor
Las bases de datos vectoriales sin servidor ofrecen varias características clave que las distinguen de otros sistemas de gestión de datos:
- Almacenamiento Vectorial: Utilizan vectores para representar datos, permitiendo operaciones de búsqueda y comparación más eficientes.
- Escalabilidad Automática: Se escalan automáticamente según la demanda, garantizando un rendimiento óptimo sin intervención manual.
- Capacidad de Búsqueda de Similitudes: Permite encontrar elementos similares o cercanos en el espacio vectorial, ideal para aplicaciones de recomendación y búsqueda por similitud.
- Sin Gestión de Infraestructura: Los usuarios no necesitan preocuparse por la gestión del hardware o el software, ya que todo está manejado por el proveedor en la nube.
- Costo Eficiente: Se cobran solo por el uso real, optimizando los costos operativos y eliminando gastos innecesarios en infraestructura.
Aplicaciones Comunes de las Bases de Datos Vectoriales Sin Servidor
Las bases de datos vectoriales sin servidor son utilizadas en una amplia gama de aplicaciones:
- Sistemas de Recomendación: Identifican productos, contenidos o usuarios similares para mejorar la experiencia del usuario.
- Búsqueda por Imagen: Buscan imágenes similares a una imagen dada, útil en aplicaciones de comercio electrónico y búsqueda visual.
- Análisis de texto y procesamiento de lenguaje natural (NLP): Representan palabras y frases en vectores para realizar tareas como búsqueda de similitud semántica.
- Sistemas de Detección de Fraude: Identifican patrones inusuales y anomalías en datos transaccionales.
- Reconocimiento de Vocecara: Utilizan estructuras vectoriales para comparar y reconocer voces en aplicaciones de asistencia virtual y seguridad.
Ventajas de las Bases de Datos Vectoriales Sin Servidor
Las bases de datos vectoriales sin servidor ofrecen varias ventajas significativas:
- Alto Rendimiento: Las operaciones de búsqueda y comparación son más rápidas y eficientes gracias a la representación vectorial de los datos.
- Flexibilidad: Pueden manejar diversos tipos de datos, desde imágenes y texto hasta señales de sensores y más.
- Facilidad de Uso: La gestión sin servidor simplifica la implementación y el mantenimiento, permitiendo a los desarrolladores enfocarse en la lógica de negocio.
- Coste Eficiente: El modelo de pago por uso reduce los costos iniciales y operativos.
- Escalabilidad Rápida: Se pueden escalar de manera transparente para manejar picos de demanda sin interrupciones.
Arquitectura de una Base de Datos Vectorial Sin Servidor
La arquitectura de una base de datos vectorial sin servidor consta de varios componentes clave:
- Ingesta de Datos: Los datos se transforman y se convierten en vectores antes de ser almacenados en la base de datos.
- Almacenamiento de Vectores: Los vectores se almacenan en estructuras de datos optimizadas para búsquedas eficientes.
- Sistema de Índices: Se utilizan índices para acelerar las búsquedas de similitudes y vecinos más cercanos.
- API de Consulta: Proporciona un interfaz para realizar consultas y obtener resultados en tiempo real.
- Capa de Gestión Sin Servidor: Maneja la escalabilidad, el rendimiento y la seguridad de la base de datos de manera transparente.
Desafíos en la Implementación de Bases de Datos Vectoriales Sin Servidor
A pesar de sus ventajas, la implementación de bases de datos vectoriales sin servidor también presenta desafíos:
- Optimización de Índices: Asegurar que los índices sean eficientes y precisos puede ser complejo, especialmente con grandes volúmenes de datos.
- Gestión de Latencia: Mantener tiempos de respuesta bajos es crucial para aplicaciones en tiempo real.
- Seguridad y Privacidad: Proteger los datos sensibles y cumplir con las regulaciones de privacidad es un desafío constante.
- Transformación de Datos: Convertir datos en vectores puede ser un proceso complejo y requiere algoritmos de transformación eficientes.
- Mantenimiento y Actualización: Asegurar que la base de datos se mantenga actualizada y optimizada a medida que cambian las necesidades del negocio.
¿Qué diferencia hay entre un servidor y una base de datos?

La diferencia entre un servidor y una base de datos es fundamental para entender cómo funcionan los sistemas informáticos modernos. Un servidor es un sistema informático que proporciona recursos, datos, servicios o programas a otros computadores, conocidos como clientes, en una red. Un servidor puede manejar diversas tareas, como alojar sitios web, manejar correos electrónicos, compartir archivos, y más. Por otro lado, una base de datos es un conjunto organizado de datos que se almacenan y acceden electrónicamente. Las bases de datos están diseñadas para facilitar la recuperación, actualización y gestión de datos de manera eficiente y segura.
Funciones Principales de un Servidor
Los servidores cumplen diversas funciones esenciales en la infraestructura de TI:
- Alojamiento de Sitios Web: Los servidores web alojan páginas web y responden a las solicitudes de navegadores de clientes.
- Correo Electrónico: Los servidores de correo electrónico gestionan el envío y recepción de mensajes.
- Compartir Archivos: Los servidores de archivos permiten el acceso y compartir de documentos entre múltiples usuarios.
- Aplicaciones: Los servidores de aplicaciones ejecutan y gestionan aplicaciones empresariales y de consumo.
- Seguridad: Los servidores de autenticación y firewall protegen la red de acceso no autorizado y amenazas.
Funciones Principales de una Base de Datos
Las bases de datos tienen funciones específicas diseñadas para gestionar y manipular datos:
- Almacenamiento de Datos: Las bases de datos almacenan datos de manera organizada y estructurada.
- Recuperación de Datos: Facilitan la búsqueda y recuperación de datos de forma rápida y eficiente.
- Actualización de Datos: Permiten la modificación y actualización de datos sin afectar la integridad de la base de datos.
- Seguridad de Datos: Implementan medidas de seguridad para proteger los datos contra accesos no autorizados y pérdida de datos.
- Integridad de Datos: Mantienen la consistencia y exactitud de los datos mediante reglas y restricciones.
Estructura y Arquitectura
La estructura y arquitectura de servidores y bases de datos varían significativamente:
- Servidores: Pueden ser físicos o virtuales, y generalmente incluyen hardware potente y software específico para manejar cargas de trabajo intensas.
- Bases de Datos: Se organizan en tablas, registros y campos, con un sistema de gestión de bases de datos (SGBD) que controla el acceso y manipulación de datos.
- Diseño de Red: Los servidores están diseñados para funcionar en redes, mientras que las bases de datos pueden ser parte de un sistema distribuido o centralizado.
- Escalabilidad: Los servidores pueden escalarse horizontalmente (añadiendo más servidores) o verticalmente (mejorando el hardware), mientras que las bases de datos pueden escalarse mediante particionamiento o replicación.
- Optimización: Los servidores se optimizan para rendimiento y disponibilidad, mientras que las bases de datos se optimizan para consultas eficientes y transacciones seguras.
Interacción entre Servidor y Base de Datos
La interacción entre un servidor y una base de datos es crítica para muchas aplicaciones:
- Comunicación: Los servidores se comunican con las bases de datos a través de protocolos y queries para manipular datos.
- Acceso a Datos: Los servidores pueden acceder a múltiples bases de datos, cada una gestionando diferentes tipos de datos.
- Seguridad: Ambos elementos implementan capas de seguridad para proteger la información y los servicios.
- Rendimiento: La eficiencia de la interacción entre servidor y base de datos afecta directamente el rendimiento del sistema.
- Integración: Pueden integrarse con otras tecnologías y servicios para mejorar la funcionalidad y la eficiencia.
Herramientas y Tecnologías Relacionadas
Existen diversas herramientas y tecnologías que facilitan el uso y gestión de servidores y bases de datos:
- Sistemas Operativos para Servidores: Linux, Windows Server, y macOS Server son comunes.
- Sistemas de Gestión de Bases de Datos (SGBD): MySQL, PostgreSQL, Oracle, y SQL Server son populares.
- Herramientas de Monitorización: Nagios, Prometheus, y Zabbix para servidores, y MySQL Workbench, pgAdmin para bases de datos.
- Herramientas de Backup y Recuperación: Bacula, Amanda, y Veritas NetBackup para servidores, y mysqldump, pg_dump para bases de datos.
- Herramientas de Seguridad: Firewalls, antivirus, y sistemas de gestión de claves para proteger tanto servidores como bases de datos.
¿Qué son los datos vectoriales?
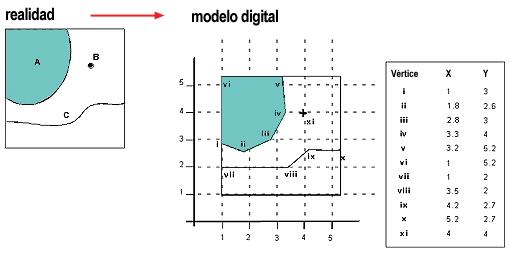
Los datos vectoriales son un tipo de representación cartográfica utilizada en SIG (Sistemas de Información Geográfica) para describir la geografía a través de puntos, líneas y polígonos. Cada uno de estos elementos, conocidos como entidades vectoriales, tiene una geometría y una serie de atributos asociados. Los puntos representan entidades geográficas discretas como ciudades o pozos de agua. Las líneas se usan para trazar caminos, ríos y límites. Los polígonos definen áreas como bosques, estados o países. A diferencia de los datos de malla raster, que dividen la superficie de la Tierra en una cuadrícula de celdas, los datos vectoriales son más precisos y flexibles, lo que los hace ideales para aplicaciones que requieren detalles geográficos específicos.
1. Tipos de Entidades Vectoriales
Los datos vectoriales se componen principalmente de tres tipos de entidades: puntos, líneas y polígonos. Cada tipo tiene su propia funcionalidad y uso específico:
- Puntos: Representan ubicaciones precisas, como hidrante, postes eléctricos o muchoos de interés. Son ideales para mapear elementos discretos.
- Líneas: Se utilizan para trazar trayectorias, como rutas de transporte, ríos o límites políticos. Las líneas son útiles para representar elementos lineales y conectivos.
- Polígonos: Definen áreas delimitadas, como parques, estados o zonas de influencia. Polígonos son esenciales para representar regiones con contornos definidos.
2. Representación Geométrica
La representación geométrica de los datos vectoriales es fundamental para su precisión y funcionalidad:
- Coordenadas X-Y: Cada entidad vectorial se define mediante coordenadas X-Y que especifican su ubicación en un sistema de referencia geográfico o cartográfico.
- Sistemas de Coordenadas: Los datos vectoriales pueden usar sistemas de coordenadas como el WGS 84 (para latitud y longitud) o sistemas locales basados en UTM (Universal Transverse Mercator).
- Topología: La topología se refiere a las relaciones espaciales entre las entidades, como la continuidad de las líneas o la adyacencia de los polígonos, lo que es crucial para la integridad de los datos.
3. Atributos de los Datos Vectoriales
Además de su geometría, cada entidad vectorial puede tener atributos asociados que proporcionan información adicional:
- Identificación: Un identificador único (ID) que permite referirse a cada entidad de manera unívoca en bases de datos y aplicaciones.
- Propiedades Inherentes: Atributos como el nombre, tipo o uso de la entidad, que son específicos de la naturaleza del objeto geográfico.
- Datos Asociados: Información adicional que puede incluir Textarea, ソンシ (es un error, omitir esta línea) o cualquier otro dato relevante para el análisis o la gestión.
4. Ventajas de los Datos Vectoriales
Los datos vectoriales ofrecen varias ventajas sobre otros tipos de datos geográficos:
- Precision: Permiten una representación detallada y precisa de la geografía, ideal para aplicaciones que requieren alta precisión.
- Flexibilidad: Los datos vectoriales son fáciles de modificar y actualizar, lo que facilita la gestión y el mantenimiento de la información geográfica.
- Eficiencia en Almacenamiento: Comparado con los datos raster, los datos vectoriales suelen ocupar menos espacio de almacenamiento y consumir menos recursos en el procesamiento.
5. Aplicaciones de los Datos Vectoriales
Los datos vectoriales son ampliamente utilizados en diversas aplicaciones geográficas:
- Cartografía: La creación de mapas detallados y precisos para la navegación, el urbanismo y la planificación de infraestructuras.
- Análisis Espacial: Utilización en modelado y análisis geográfico para identificar patrones, tendencias y relaciones espaciales.
- Gestión de Recursos: Apoyo en la gestión de recursos naturales, la conservación ambiental y la planificación de usos del suelo.
Preguntas Frecuentes de Nuestra Comunidad (FAQ)
SvectorDB es una solución de base de datos vectorial sin servidor que permite a desarrolladores y empresas almacenar, indexar y buscar vectores de datos de manera eficiente. A diferencia de las bases de datos tradicionales, SvectorDB se especializa en la gestión de datos de alta dimensión, como representaciones vectoriales de imágenes, texto y señales, facilitando tareas de búsqueda por similitud, recomendación y clasificación. La arquitectura sin servidor de SvectorDB significa que no necesitas preocuparte por la gestión de infraestructura; simplemente se encarga de escalar automáticamente para manejar cargas de trabajo variables, lo que te permite centrarte en desarrollar tu aplicación. Las ventajas de usar SvectorDB incluyen su facilidad de uso y rapidez de implementación, ya que puedes tener una base de datos vectorial funcional en menos de 2 minutos. Además, su modelo sin servidor elimina la necesidad de administrar servidores o clusters, lo que reduce significativamente la complejidad operativa y los costos de mantenimiento. SvectorDB ofrece un alto rendimiento y latencia baja en consultas de similitud, así como una experiencia de usuario fluida para aplicaciones que requieren búsqueda y recomendación en tiempo real. También destaca por su escalabilidad automática, permitiendo manejar aumentos en la carga de trabajo sin intervención manual. Integrar SvectorDB en tu aplicación existente es un proceso sencillo y rápido. Primero, necesitas crear una cuenta en la plataforma de SvectorDB y configurar tu base de datos. Luego, puedes utilizar las APIs proporcionadas para insertar, buscar y manejar vectores en tu base de datos. SvectorDB soporta lenguajes de programación populares como Python, JavaScript y Java, por lo que podrás encontrar bibliotecas y SDKs que facilitan la integración. Además, la documentación y los ejemplos de código disponibles en la plataforma te guiarán paso a paso en el proceso de integración, asegurando que puedas empezar a usar SvectorDB de manera eficiente en poco tiempo. SvectorDB se utiliza ampliamente en una variedad de casos de uso que requieren la gestión y búsqueda de datos de alta dimensión. Algunos de los más comunes incluyen recomendaciones personalizadas en plataformas de streaming y e-commerce, donde SvectorDB ayuda a encontrar items similares o relevantes para los usuarios. También es útil en sistemas de búsqueda por imagen y búsqueda visual, donde los vectores representan características visuales de imágenes para encontrar coincidencias. En el campo de la procesamiento de lenguaje natural (NLP), SvectorDB puede almacenar y buscar embeddings de texto para aplicaciones como chatbots y asistentes virtuales. Otro caso de uso importante es la detección de anomalías en datos de sensores y logs, donde SvectorDB identifica patrones inusuales de manera eficiente.¿Cuáles son las ventajas de usar SvectorDB en lugar de otras bases de datos vectoriales?
¿Cómo puedo integrar SvectorDB en mi aplicación existente?
¿Cuáles son los casos de uso típicos de SvectorDB?
Escrito por:

Deja una respuesta
Nuestros Artículos Recomendados