| Slack¿Qué es OCR y para qué se utiliza busca una imagen en Internet que contenga texto y convierte a texto? 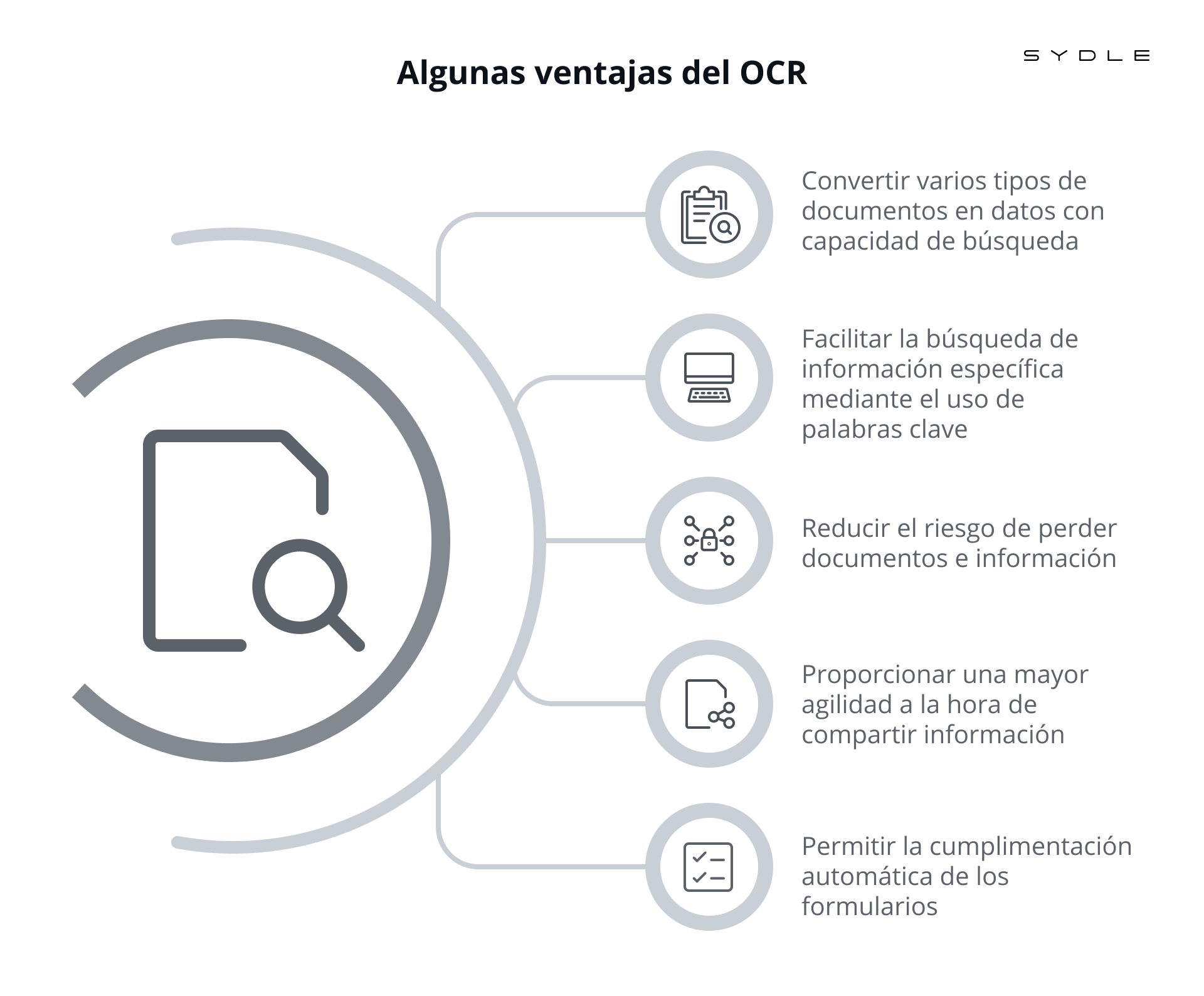
¿Qué es OCR y para qué se utiliza? OCR, que es el acrónimo de Optical Character Recognition (Reconocimiento Óptico de Caracteres), es una tecnología que convierte imágenes de texto impreso o escrito a mano en texto digital editable. Este proceso es fundamental para automatizar la digitalización de documentos, facilitando su búsqueda, edición y almacenamiento. El OCR se utiliza en una amplia variedad de aplicaciones, desde la digitalización de libros y archivos históricos hasta la automatización de procesos en empresas y la extracción de información de facturas y recibos. Búsqueda de una imagen en Internet que contenga texto y su conversión a texto Para ilustrar el proceso de OCR, supongamos que encontramos una imagen en Internet que contiene un texto impreso. Por ejemplo, una fotografía de una página de un libro antiguo. Al aplicar la tecnología OCR a esta imagen, el software analiza la imagen, identifica y reconoce los caracteres, y los convierte en texto digital. El resultado es un archivo de texto que se puede editar, buscar y procesar con programas de procesamiento de texto como Microsoft Word o Google Docs. ¿Cómo funciona el OCR?El OCR funciona a través de varios pasos: - Preprocesamiento de la imagen: Se realizan operaciones como el ajuste de brillo, contraste y eliminación de ruido para mejorar la calidad de la imagen.
- Detección de caracteres: El software identifica las zonas de la imagen que contienen texto y las segmenta en caracteres individuales.
- Reconocimiento de caracteres: Utilizando algoritmos y bases de datos, el OCR compara los caracteres detectados con modelos conocidos para determinar qué letras o números representan.
- Posprocesamiento: Se corrigen errores y se mejora la precisión del texto reconocido, a menudo mediante técnicas de aprendizaje automático.
Aplicaciones del OCR en la vida cotidianaEl OCR tiene múltiples aplicaciones en la vida cotidiana: - Digitización de documentos: Facilita la conversión de documentos físicos a formato digital, permitiendo su almacenamiento y búsqueda eficientes.
- Accesibilidad: Ayuda a personas con discapacidades visuales a acceder al contenido impreso a través de lectores de pantalla.
- Automatización de procesos: Se utiliza en la automatización de tareas como el procesamiento de facturas y recibos en empresas.
- Traducción de textos: Permite la traducción de textos desde imágenes a diferentes idiomas.
- Archivado histórico: Facilita la preservación y acceso a documentos históricos y literarios.
Desafíos y limitaciones del OCRA pesar de sus avances, el OCR aún enfrenta desafíos y limitaciones: - Calidad de la imagen: Imágenes borrosas o con baja resolución pueden dificultar el reconocimiento de caracteres.
- Estilos de escritura: El OCR puede tener dificultades con fuentes o estilos de escritura no estándar.
- Idiomas y caracteres especiales: El reconocimiento de idiomas no latinos y caracteres especiales puede ser menos preciso.
- Errores de reconocimiento: Aunque los algoritmos han mejorado, aún pueden ocurrir errores, especialmente en textos complejos.
- Costo y recursos: Implementar soluciones OCR avanzadas puede ser costoso y requerir recursos técnicos significativos.
Herramientas y plataformas de OCRExisten varias herramientas y plataformas que ofrecen servicios de OCR: - Adobe Acrobat: Ofrece funciones avanzadas de OCR para convertir PDFs a texto editable.
- Tesseract: Una librería de código abierto desarrollada por Google que proporciona un OCR de alta calidad y es altamente personalizable.
- Google Cloud Vision API: Ofrece servicios de OCR en la nube, con capacidad para procesar grandes volúmenes de datos.
- AABBYY FineReader: Una herramienta profesional para la digitalización y conversión de documentos, conocida por su alta precisión.
- Microsoft Azure Computer Vision: Proporciona servicios de OCR integrados en la plataforma de Azure, ideal para aplicaciones empresariales.
Impacto del OCR en la eficiencia y la productividadEl OCR ha tenido un impacto significativo en la eficiencia y la productividad: - Reducción de tiempo: Automatiza procesos que antes eran manuales y laboriosos, ahorrando tiempo y recursos.
- Mejora en la precisión: Reduce los errores humanos en la transcripción de texto, aumentando la confiabilidad de los datos.
- Acceso a información: Facilita el acceso a información histórica y legal, mejorando la investigación y el análisis.
- Optimización de almacenamiento: Reduce la necesidad de almacenamiento físico de documentos, ahorrando espacio y costos.
- Mejora en la colaboración: Permite la colaboración en tiempo real en documentos digitales, mejorando la eficacia de los equipos.
¿Cuál es la IA que lee imágenes?
La IA que lee imágenes se conoce generalmente como Visión por Computadora. Esta tecnología utiliza algoritmos avanzados para analizar y interpretar imágenes y videos, permitiendo a las máquinas comprender el contenido visual del mismo modo que lo hace un humano. Las aplicaciones de la Visión por Computadora son extensas y abarcan desde la detección de objetos y el reconocimiento facial hasta la clasificación de imágenes y la generación de descripciones. En el campo de la inteligencia artificial, las redes neuronales convolucionales (CNN) son una de las herramientas más utilizadas para este propósito, ya que son capaces de aprender características visuales complejas a partir de grandes conjuntos de datos. Algunas de las empresas líderes en este área incluyen Google con su plataforma TensorFlow, Microsoft con Azure Cognitive Services, y Amazon con AWS Rekognition. ¿Qué es la Visión por Computadora?La Visión por Computadora es un campo de la inteligencia artificial que se enfoca en la interpretación y comprensión de imágenes y videos por parte de máquinas. Este proceso implica varios pasos, como la captura de imágenes, el preprocesamiento de datos, la detección de características y la clasificación. Las técnicas utilizadas en la Visión por Computadora incluyen: - Detección de objetos: Identificación y localización de elementos específicos dentro de una imagen.
- Reconocimiento facial: Identificación de rostros humanos y su correspondencia con individuos específicos.
- Clasificación de imágenes: Categorización de imágenes en diferentes clases o etiquetas.
- Segmentación de imágenes: División de una imagen en múltiples segmentos o regiones para su análisis detallado.
- Generación de descripciones: Creación de descripciones textuales coherentes basadas en el contenido visual de una imagen.
¿Cuáles son las principales tecnologías utilizadas en la Visión por Computadora?Las principales tecnologías utilizadas en la Visión por Computadora incluyen: - Redes Neuronales Convolucionales (CNN): Modelos de aprendizaje profundo que son especialmente efectivos en la detección de características visuales.
- Aprendizaje por Transferencia: Técnica que aprovecha modelos pre-entrenados para tareas similares, acelerando el proceso de entrenamiento y mejorando la precisión.
- Aprendizaje Supervisado: Enfoque en el que los modelos son entrenados con conjuntos de datos etiquetados para realizar tareas específicas.
- Aprendizaje No Supervisado: Método que busca identificar patrones y estructuras en datos no etiquetados.
- Aprendizaje por Refuerzo: Enfoque que involucra la optimización de acciones basadas en recompensas y castigos.
¿Cuáles son las aplicaciones más comunes de la Visión por Computadora?Las aplicaciones más comunes de la Visión por Computadora incluyen: - Seguridad y vigilancia: Detección de intrusos, reconocimiento facial y análisis de comportamientos sospechosos.
- Medicina: Diagnóstico de enfermedades a partir de imágenes médicas, como radiografías o resonancias magnéticas.
- Automoción: Detección de objetos en sistemas de conducción autónoma para evitar colisiones.
- Marketing y publicidad: Análisis de imágenes en redes sociales para comprender tendencias y preferencias de los consumidores.
- Robótica: Navegación y manipulación de objetos en entornos complejos.
¿Cuáles son los desafíos en la Visión por Computadora?Los desafíos más significativos en la Visión por Computadora incluyen: - Variabilidad en los datos: Las imágenes pueden variar en iluminación, ángulo y condiciones ambientales, lo que complica la detección de características.
- Escasez de datos etiquetados: El entrenamiento de modelos de aprendizaje profundo requiere grandes conjuntos de datos etiquetados, los cuales pueden ser costosos y difíciles de obtener.
- Interpretación de contextos: La comprensión de contextos complejos y sutiles en imágenes sigue siendo un desafío importante.
- Ruido y distorsión: Las imágenes pueden contener ruido o estar distorsionadas, afectando la precisión de los algoritmos.
- Privacidad y ética: El uso de imágenes personales y la recolección de datos plantean preocupaciones sobre privacidad y ética.
¿Cuáles son los beneficios de la Visión por Computadora?Los beneficios de la Visión por Computadora incluyen: - Eficiencia y precisión: Automatización de tareas que antes requerían intervención humana, mejorando la velocidad y la precisión.
- Costo-efectividad: Reducción de costos operativos al minimizar la necesidad de mano de obra humana en ciertas tareas.
- Análisis en tiempo real: Capacidad de procesar y interpretar imágenes en tiempo real, lo que es crucial en aplicaciones como la conducción autónoma.
- Mejora en la seguridad: Aumento de la seguridad en entornos industriales y de consumo a través de la detección temprana de peligros.
- Innovación en la medicina: Avances en el diagnóstico y tratamiento de enfermedades a partir de imágenes médicas de alta calidad
¿Cómo obtener texto a partir de una imagen?
Obtener texto a partir de una imagen es un proceso conocido como OCR (Optical Character Recognition, o Reconocimiento Óptico de Caracteres). Este método convierte imágenes que contienen texto en caracteres digitales que se pueden editar y manipular. A continuación, se detallan los pasos y herramientas más comunes para realizar este proceso: 1. Preparación de la Imagen:
- Calidad de la Imagen: Asegúrate de que la imagen esté clara y bien iluminada. Una imagen de baja calidad puede dificultar el proceso de reconocimiento.
- Formateo: Si es necesario, ajusta el tamaño y la orientación de la imagen para facilitar el procesamiento.
- Eliminación de Ruido: Utiliza herramientas de edición de imágenes para eliminar cualquier ruido o elementos no deseados que puedan interrumpir el OCR. 2. Selección de la Herramienta de OCR:
- Software de Escritorio: Programas como Adobe Acrobat, ABBYY FineReader, y Tesseract (gratuito y de código abierto) son opciones populares.
- Herramientas en Línea: Sitios web como OnlineOCR.net, OCR.space, y Google Drive ofrecen servicios de OCR gratuitos y fáciles de usar.
- Aplicaciones Móviles: Apps como Microsoft Lens y Google Keep tienen funciones de OCR integradas. 3. Proceso de OCR:
- Carga de la Imagen: Importa la imagen a la herramienta de OCR seleccionada.
- Ejecución del OCR: Inicia el proceso de reconocimiento. La mayoría de las herramientas tienen una opción para ejecutar el OCR automáticamente.
- Corrección de Errores: Revisa el texto resultante y corrige cualquier error que pueda haber ocurrido durante el proceso. 4. Salida y Edición:
- Formato de Salida: Elige el formato en el que deseas guardar el texto, como DOCX, PDF, o TXT.
- Edición: Utiliza un procesador de texto para editar y formatear el texto según sea necesario. 5. Guardado y Uso:
- Guardado: Guarda el archivo de texto en una ubicación segura.
- Uso: Utiliza el texto extraído para tus propósitos, ya sea para edición, análisis, o cualquier otro fin. 1. Preparación de la Imagen para el OCRPara obtener los mejores resultados con el OCR, es crucial preparar la imagen de manera adecuada. Asegúrate de que la imagen esté clara y bien iluminada. Si la imagen es borrosa o tiene sombras, el proceso de reconocimiento puede ser menos preciso. Utiliza herramientas de edición de imágenes para mejorar la calidad: - Ajustar el tamaño y la orientación: Si la imagen está distorsionada o está en una orientación incorrecta, ajusta estos parámetros.
- Eliminar ruido: Usa filtros para eliminar cualquier ruido o elementos no deseados que puedan interrumpir el OCR.
- Aumentar el contraste: Un mayor contraste entre el texto y el fondo puede mejorar la precisión del reconocimiento.
2. Selección de la Herramienta de OCR más AdecuadaElige una herramienta de OCR que se adapte a tus necesidades y presupuesto. Hay opciones tanto de software de escritorio como de herramientas en línea y aplicaciones móviles: - Software de Escritorio: Programas como Adobe Acrobat, ABBYY FineReader, y Tesseract son potentes y ofrecen una amplia gama de funciones.
- Herramientas en Línea: Sitios web como OnlineOCR.net y OCR.space son fáciles de usar y gratuitos para tareas sencillas.
- Aplicaciones Móviles: Apps como Microsoft Lens y Google condem tienen funciones de OCR integradas y son ideales para tareas rápidas.
3. Ejecución del Proceso de OCRUna vez que hayas preparado la imagen y seleccionado la herramienta de OCR, el siguiente paso es ejecutar el proceso: - Carga de la Imagen: Importa la imagen a la herramienta de OCR seleccionada. La mayoría de las herramientas permiten arrastrar y soltar la imagen o seleccionarla desde tu dispositivo.
- Ejecución del OCR: Inicia el proceso de reconocimiento. La mayoría de las herramientas tienen una opción para ejecutar el OCR automáticamente, pero algunas ofrecen ajustes avanzados para mejorar la precisión.
- Corrección de Errores: Revisa el texto resultante y corrige cualquier error que pueda haber ocurrido durante el proceso. Los errores comunes incluyen caracteres mal interpretados o espacios incorrectos.
Después de obtener el texto a partir de la imagen, es probable que necesites editar y formatear el resultado: - Formato de Salida: Elige el formato en el que deseas guardar el texto, como DOCX, PDF, o TXT. Algunas herramientas de OCR permiten exportar directamente en estos formatos.
- Corrección de Errores: Utiliza un procesador de texto para revisar y corregir cualquier error en el texto extraído. Esto puede incluir corregir errores de ortografía, puntuación, y formato.
- Formateo: Ajusta el formato del texto según tus necesidades, como cambiar el tamaño de fuente, estilo, y añadir encabezados o listas.
Una vez que hayas editado y formateado el texto, es importante guardar el archivo de manera segura y utilizarlo según tus propósitos: - Guardado: Guarda el archivo de texto en una ubicación segura, como tu computadora o una nube. Asegúrate de darle un nombre claro y descriptivo.
- Uso: Utiliza el texto extraído para tus propósitos, ya sea para edición, análisis, o cualquier otro fin. El texto puede ser utilizado en documentos, presentaciones, o incluso
¿Qué herramienta de IA permite generar imágenes a partir de texto?
DALL-E es una de las herramientas de IA más conocidas y avanzadas que permite generar imágenes a partir de texto. Desarrollada por OpenAI, DALL-E es capaz de crear una amplia variedad de imágenes, desde paisajes realistas hasta conceptos abstractos, basándose únicamente en una descripción textual. Esta herramienta utiliza una red neuronal entrenada en una gran cantidad de datos para entender las relaciones entre los objetos y las palabras, lo que le permite generar imágenes coherentes y visualmente atractivas. DALL-E es especialmente útil para diseñadores, artistas y creadores de contenido que buscan inspiración o material visual sin necesidad de habilidades de dibujo o fotografía. ¿Cómo funciona DALL-E?DALL-E funciona mediante un modelo de aprendizaje profundo que ha sido entrenado con una vasta cantidad de imágenes y sus descripciones correspondientes. Cuando se le proporciona un texto, DALL-E analiza las palabras y genera una imagen que refleja lo descrito. El proceso involucra varios pasos: - Análisis del texto: El modelo descompone el texto en tokens y comprende el significado de cada palabra y frase.
- Generación de características: Se generan características visuales basadas en el análisis del texto.
- Composición de la imagen: Estas características se combinan para crear una imagen coherente y visualmente atractiva.
- Refinamiento: El modelo ajusta la imagen para asegurarse de que sea lo más fiel posible a la descripción original.
- Salida final: La imagen final se presenta al usuario.
Alternativas a DALL-EAunque DALL-E es una de las herramientas más avanzadas, existen otras alternativas que también permiten generar imágenes a partir de texto: - Midjourney: Ofrece una interfaz amigable y resultados rápidos, ideal para creadores de contenido y diseñadores.
- Stable Diffusion: Es de código abierto y permite una mayor personalización y control sobre el proceso de generación.
- Imagen: Desarrollada por Google, ofrece resultados de alta calidad y una amplia variedad de estilos.
- Artbreeder: Combina imágenes existentes para crear nuevas, permitiendo un alto nivel de creatividad.
- DeepAI Image Generator: Proporciona una gama de herramientas y estilos diferentes, ideal para experimentación.
Aplicaciones de las herramientas de IA para generar imágenesLas herramientas de IA que generan imágenes a partir de texto tienen una amplia gama de aplicaciones en diversos campos: - Diseño gráfico: Creación de ilustraciones, logotipos y elementos visuales para proyectos de diseño.
- Marketing digital: Generación de contenido visual para campañas publicitarias y redes sociales.
- Arte y entretenimiento: Producción de arte digital, concept art y animaciones.
- Desarrollo de videojuegos: Creación de assets visuales y entornos para juegos.
- Investigación y educación: Generación de imágenes para ilustrar conceptos científicos y educativos.
Ventajas y desventajas de usar herramientas de IA para generar imágenesEl uso de herramientas de IA para generar imágenes tiene tanto ventajas como desventajas: - Ventajas:
- Velocidad: Generan imágenes rápidamente, ahorrando tiempo en el proceso creativo.
- Costo-efectividad: Reducen los costos asociados con la contratación de artistas o fotógrafos.
- Accesibilidad: Son fáciles de usar y no requieren habilidades técnicas avanzadas.
- Desventajas:
- Calidad limitada: Aunque están mejorando, las imágenes generadas pueden no tener la calidad de las creadas manualmente.
- Falta de originalidad: Las imágenes pueden resultar predecibles o similares a otras generadas por la misma herramienta.
- Ética y derechos de autor: Pueden surgir preocupaciones sobre el uso de imágenes generadas por IA en contextos comerciales.
Consideraciones éticas y legales al usar herramientas de IA para generar imágenesEl uso de herramientas de IA para generar imágenes también conlleva consideraciones éticas y legales: - Propiedad intelectual: Es importante entender quién tiene los derechos sobre las imágenes generadas y cómo se pueden utilizar.
- Privacidad: Si las imágenes incluyen representaciones de personas, se deben respetar los derechos de privacidad y obtener los permisos necesarios.
- Uso responsable: Es crucial evitar el uso de estas herramientas para generar contenido dañino, engañoso o inapropiado.
- Transparencia: Es recomendable ser transparente sobre el uso de IA en la creación de imágenes, especialmente en contextos donde la autenticidad es importante.
- Bias y representación: Es importante estar atentos a posibles sesgos en las imágenes generadas y trabajar para asegurar una representación equitativa y diversa.
Lo que pregunta nuestra comunidad¿Qué es ImgChatIO?ImgChatIO es una innovadora aplicación que combina las tecnologías de OCR (Optical Character Recognition) y IA (Inteligencia Artificial) para extraer texto de imágenes y permitir una interacción conversacional con un asistente de IA. Esta herramienta es especialmente útil para personas que necesitan extraer información de documentos, imágenes o cualquier tipo de contenido visual y convertirlo en texto editable. Además, el asistente de IA proporciona respuestas y ayuda en tiempo real, facilitando la comprensión y el manejo de la información extraída. ¿Cómo funciona el OCR en ImgChatIO?El OCR (Optical Character Recognition) en ImgChatIO es una tecnología avanzada que permite a la aplicación reconocer y convertir texto impreso o escrito a mano en imágenes en texto digital. Este proceso implica varios pasos: la aplicación primero analiza la imagen para identificar los caracteres, luego los reconoce y los convierte en texto que puede ser editado y utilizado. La precisión del OCR en ImgChatIO es alta, lo que asegura que el texto extraído sea fiel al original, minimizando errores y mejorando la eficiencia en la gestión de información visual. ¿Qué tipo de imágenes puedo usar con ImgChatIO?Puedes utilizar una amplia variedad de imágenes con ImgChatIO, incluyendo fotografías, escaneos de documentos, capturas de pantalla y más. La aplicación está diseñada para manejar diferentes formatos de imagen, como JPEG, PNG, GIF, entre otros. Ya sea que necesites extraer texto de un libro, un artículo de periódico, un menú de restaurante o cualquier otro tipo de documento, ImgChatIO es capaz de procesar y convertir el contenido visual en texto de alta calidad. Además, la aplicación también puede manejar imágenes con diferentes calidades y resoluciones, adaptándose a las necesidades del usuario. ¿Cómo interactúo con el asistente de IA en ImgChatIO?La interacción con el asistente de IA en ImgChatIO es sencilla y intuitiva. Una vez que has extraído el texto de una imagen, puedes comenzar a chatear con el asistente de IA simplemente escribiendo tus preguntas o instrucciones en el chat. El asistente responderá de manera inmediata, proporcionando respuestas detalladas y precisas. Además, el asistente puede ayudarte a interpretar el contenido extraído, ofrecer sugerencias, realizar búsquedas adicionales y más. Esta funcionalidad hace de ImgChatIO una herramienta versátil y valiosa para una amplia gama de aplicaciones, desde el trabajo académico hasta la gestión de documentos en el entorno empresarial. Cofundadora y CEO de MPF. Hábil en planificación empresarial, habilidades analíticas, finanzas corporativas, planificación estratégica y estrategia de marketing. Graduada por el Massachusetts Institute of Technology - Sloan School of Management. Global Marketing Senior Manager en Boston Consulting Group (BCG) - Me apasiona ser consultor en creación de empresas - ayudo a nuevos empresarios a gestionar sus empresas.
|



Nuestros Artículos Recomendados